Summary
I will cover a practical technique to implement "lambda-like" HTTP services behind RPC-as-message-passing gateways with ZIO and Tapir libraries. The advantage of such an approach is that you can keep the business logic and interfaces of the service(s) separate from the transport layer; and since the eventual transport layer is HTTP, simultaneously provide nice local testing tools and API documentation. The technique will involve some complexity on the type level, and we will try and evaluate the tradeoffs at the end of the post. Code is here.
Background
This post is inspired by a situation that came up at work. We have APIs that are accessible over HTTP but are backed by message queues. The "gateway" to translate is almost transparent (± a few extra headers) for both the caller and callee and we want to take advantage of existing HTTP tooling (OpenAPI specs, test clients). A previous version would manually translate the HTTP semantics (header parsing, query parameters, etc.) which was quite fiddly and there was no API spec that clients could use.
The Tapir project is a Scala library that allows you to declaratively define service endpoints (separately from
their implementation) and interpret both HTTP servers and HTTP clients using a variety of different libraries (usually
with a flavour matrix of underlying HTTP library e.g. http4s, armeria or netty, and effect type e.g. Future, ZIO,
F[_] etc.). There is also support for executing HTTP
endpoints on AWS Lambda, so this idea of interpreting an HTTP endpoint definition for something that abstracts away the
actual HTTP server from you is not new.
I have also been trying out ZIO 2.0 after a long time of using cats-effect. This post will assume some
familiarity, so I will cover the basics quickly (assuming prior experience with cats-effect IO or similar).
Unlike an IO[A] which represents an unevaluated program (() => A) returning A and possibly throwing Throwable
during its eventual evaluation, a ZIO[R, E, A] is a little bit more sophisticated. It represents an unevaluated
program R => Either[E, A] that can also "die" with a Throwable but has a dedicated error channel for "business"
errors that need to be handled. The R is called an environment type and along with the error handling really sets
ZIO apart from any other effect system. It has long been known that constructors do not compose, so if your app is made
up of multiple "modules" then techniques like dependency injection or the
Cake (anti)pattern have been used to bring composition back into play. With ZIO, the R is an
intersection type on the type-level and a type-keyed map at runtime - this allows (almost) seamless composition. This
topic is easily a separate article though, so I recommend to go and read the ZIO docs and play with it yourself.
Tapir Endpoints
Suppose you have an API endpoint /foo that you can 'GET' to retrieve all the foobars in your system. (I decided to use
these classic names instead of something concrete because the concretisation probably won't help). You might be tempted
to write something like:
@app.route('/foobar')
def get_foos():
return load_foobars_from_database()
val route = path("foobar") {
get {
complete(loadFooBarsFromDatabase())
}
}
(using flask and akka-http respectively)
This is fine, and very little code, but has the following disadvantages:
- error handling is not explicit (and by looking at the type signature only you cannot determine what kind of handling to expect)
- does not help in providing an API spec to clients
- advanced features like streaming request/response bodies are typically under a different API
A Tapir endpoint is a precise model of the endpoint, covering error type, secure inputs, public inputs (query parameters, form bodies etc.), the ability (or not) to processing bodies in a streaming fashion (or even use WebSockets). Here is an example definition:
val listFooBars: PublicEndpoint[Unit, Error, List[FooBar], Any] =
endpoint
.get
.in("foobar")
.out(jsonBody[List[FooBar]].description("All of the foobars"))
.errorOut(errorBody)
Let's examine the type signature with the help of the docs (some copy-paste involved):
type Endpoint[A, I, E, O, R] = ???
type PublicEndpoint[I, E, O, -R] = Endpoint[Unit, I, E, O, R]
Ais the type of security input parametersIis the type of input parametersEis the type of error-output parametersOis the type of output parametersRare the capabilities that are required by this endpoint’s inputs/outputs, such as support for websockets or a particular non-blocking streaming implementation.Any, if there are no such requirements.
That is rather a lot of type parameters! but also something I think you can get used to quickly when you read
PublicEndpoint[Unit, Error, List[FooBar], Any] as
an endpoint with no auth, no inputs, errors of type
Error, returning aList[FooBar]with no specific requirements on runtime behaviour (such as streaming bodies).
This is also not more complex (and arguably less so) than the previous definitions, just more verbose because we've declared everything upfront instead of gradually.
Our whole foobar service (with 3 endpoints) is declared as
sealed trait Error
object Error {
case object EmptyMetadata extends Error
case class NotFound(id: UUID) extends Error
}
val uuidBody = stringBody.map(UUID.fromString(_))(_.toString)
val errorBody = jsonBody[Error]
val addFooBar: PublicEndpoint[(FooBar, String), Error, UUID, Any] =
endpoint.post
.in("foobar" / "add")
.in(jsonBody[FooBar].description("The foobar to add"))
.in(header[String]("X-Foobar-Meta").description("The metadata to add"))
.out(uuidBody.description("identifier"))
.errorOut(errorBody)
val getFooBar: PublicEndpoint[UUID, Error, FooBar, Any] =
endpoint.get
.in("foobar" / path[UUID])
.out(jsonBody[FooBar].description("The foobar, if found"))
.errorOut(errorBody)
val listFooBars: PublicEndpoint[Unit, Error, List[FooBar], Any] =
endpoint.get
.in("foobar")
.out(jsonBody[List[FooBar]].description("All of the foobars"))
.errorOut(errorBody)
And because tapir supports a Redoc interpreter, we also have an OpenAPI spec with a web UI running with the line (ignoring the few more lines required to bring up an actual web server):
RedocInterpreter().fromEndpoints[RIO[FooBarService.Environment, *]](FooBarServiceEndpoints.All, "foobar service", "0.0.1")
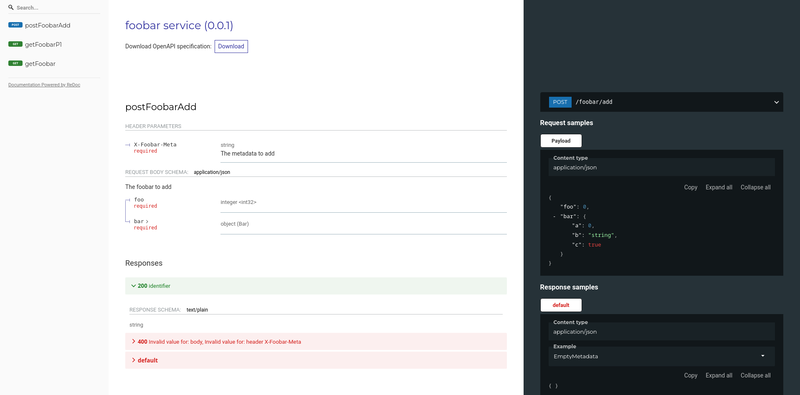
Which I think is very neat and means you can put your effort into learning type systems and not YAML schemas for OpenAPI. Or rather, you are here already, so you probably don't need to learn more about type systems 😂
There is one final detail, namely how the server "logic" is attached to an endpoint definition. This is straightforward,
the I (input) type is converted to an Either[E, O] where E is the error type and O is the output type. For the
GET /foobar endpoint, this means a function signature of Unit => F[Either[Error, List[FooBar]]].
The type complexity comes from trying to shove the ZIO[_, _, _] type into the F[_] signature of the effect type.
The choice of F[_] with one parameter is natural only because such types are pervasive (think Try, Future, IO)
across the ecosystem, but a RIO[R, *] is equivalent (and also the same as ZIO[R, Throwable, *]). The * is the
kind-projector syntax we have to use in Scala 2 to have an anonymous type so that we do not have to write out the
named type RIORA[A] = RIO[R, A] to make the RIO[_, _] "fit" into F[_]. Simples! ...
It looks like this (repeating some definitions from earlier):
type Environment = Any // not actually Any
object FooBarServiceEndpoints {
val listFooBars: PublicEndpoint[Unit, Error, List[FooBar], Any] =
endpoint.get
.in("foobar")
.out(jsonBody[List[FooBar]].description("All of the foobars"))
.errorOut(errorBody)
}
object FoobarService {
def list(): ZIO[Environment, Error, List[FooBar]] = ZIO.dieMessage("implement the service logic")
}
val endpointWithLogic: ServerEndpoint[Any, RIO[Environment, *]] =
FooBarServiceEndpoints.getFooBar.serverLogic(FooBarService.get(_).either)
That .either at the end changes ZIO[R, E, A] into a ZIO[R, Nothing, Either[E, A]] which is what Tapir expects to
have. This is actually because of the choice of effect type F[_] - it only has a single hole for the result type, so
the only way to represent an explicitly typed error is to have F[Either[Error, Success]]. The first Any type in
ServerEndpoint is the stream/whatever capability which is unused here.
Implementing a Backend
Most of the backends that Tapir supports are backed by real HTTP server implementations, and they typically support features like WebSockets and streaming bodies which are not interesting for our message-based gateway (though I wonder if you could shoehorn the web socket protocol into the message queue we are using).
The message representation that I am using for this example project is as follows:
case class Message(headers: Map[String, String], body: Array[Byte]) {
lazy val method = Method.unsafeApply(headers("X-Request-Method"))
lazy val uri = Uri.unsafeParse(headers("X-Request-URL"))
}
case class MessageResponse(inner: Message)
The method/uri fields are niceties so the code stays compact (and reuse the sttp/tapir parsers). They could live
in the message to ServerRequest converter too.
After looking at the existing implementations of backends, there are a few pieces that need to be implemented:
- How to go from our
Messageto the TapirServerRequestrepresentation that deals with headers, url parameters etc. - How to go from the response body back to
MessageResponse(calledToResponseBodyin Tapir) - How to go from a list of
ServerEndpointto a handler that can processMessage => F[MessageResponse]
All of these are implemented in MessageTapirBackend.scala and explained below.
Message => ServerRequest
The first is straightforward - we need to implement the methods on ServerRequest using the Message:
case class MessageServerRequest(message: Message, attributes: AttributeMap = AttributeMap.Empty) extends ServerRequest {
override def protocol: String = "HTTP/1.1"
override def connectionInfo: ConnectionInfo = ConnectionInfo(None, None, None)
override def underlying: Any = message
override def pathSegments: List[String] = message.uri.pathSegments.segments.map(_.v).toList
override def queryParameters: QueryParams = message.uri.params
override def attribute[T](k: AttributeKey[T]): Option[T] = attributes.get(k)
override def attribute[T](k: AttributeKey[T], v: T): ServerRequest = copy(attributes = attributes.put(k, v))
override def withUnderlying(underlying: Any): ServerRequest =
MessageServerRequest(underlying.asInstanceOf[Message], attributes)
override def method: Method = message.method
override def uri: Uri = message.uri
override def headers: Seq[Header] = message.headers.map((Header.apply _).tupled).toSeq
}
Notes:
- there is no connection-level or protocol information, so we default to 'HTTP/1.1'
- the path segments, query parameters, other headers are extracted from the underlying
Messagefrom the broker - the
AttributeMapis a sttp/tapir construct to add the ability to tag requests/responses e.g. for telemetry/tracing purposes - there is no request body handling
The request body handling is treated separately (presumably to accommodate streaming bodies), as follows:
class MessageRequestBody[R]() extends RequestBody[RIO[R, *], NoStreams] {
override val streams: capabilities.Streams[NoStreams] = NoStreams
override def toStream(serverRequest: ServerRequest): streams.BinaryStream = throw Unsupported.Streams
override def toRaw[Req](serverRequest: ServerRequest, bodyType: RawBodyType[Req]): RIO[R, RawValue[Req]] = {
val underlying = serverRequest.underlying.asInstanceOf[Message]
bodyType match {
case RawBodyType.StringBody(charset) => ZIO.succeed(new String(underlying.body, charset)).map(RawValue(_))
case RawBodyType.ByteArrayBody => ZIO.succeed(underlying.body).map(RawValue(_))
case RawBodyType.ByteBufferBody => ZIO.succeed(ByteBuffer.wrap(underlying.body)).map(RawValue(_))
case RawBodyType.InputStreamBody => ZIO.succeed(new ByteArrayInputStream(underlying.body)).map(RawValue(_))
case RawBodyType.FileBody => ZIO.die(Unsupported.Files)
case _: RawBodyType.MultipartBody => ZIO.die(Unsupported.Multipart)
}
}
}
Notes:
NoStreamsis a pre-defined capability that indicates a lack of streaming supportRawBodyType/RawValueare defined in the library- the
.underlyingisAnyso we have to explicitly cast :sadface: - there are different bodies we can get internally, and we deal with strings, byte arrays, NIO byte buffers and
InputStreams - file/multipart bodies do not make sense for our use-case (no large payloads)
- I used
ZIO.dieinstead ofZIO.failbecause really if something is unsupported it should fail the whole server
ToResponseBody[MessageResponse, _]
The second (going from the tapir representation back to a MessageResponse) is also fairly mechanical:
class MessageResponseBody() extends ToResponseBody[MessageResponse, NoStreams] {
override def fromRawValue[Resp](
v: Resp,
headers: HasHeaders,
format: CodecFormat,
bodyType: RawBodyType[Resp]
): MessageResponse = {
val arr = bodyType match {
case RawBodyType.StringBody(charset) => v.asInstanceOf[String].getBytes(charset)
case RawBodyType.ByteArrayBody => v.asInstanceOf[Array[Byte]]
case RawBodyType.ByteBufferBody => v.asInstanceOf[ByteBuffer].array()
case RawBodyType.InputStreamBody => v.asInstanceOf[InputStream].readAllBytes()
case RawBodyType.FileBody => throw Unsupported.Files
case _: RawBodyType.MultipartBody => throw Unsupported.Multipart
}
MessageResponse(Message(mkHeaders(headers), arr))
}
private def mkHeaders(headers: HasHeaders): Map[String, String] = headers.headers.map(h => h.name -> h.value).toMap
override val streams: capabilities.Streams[NoStreams] = NoStreams
override def fromStreamValue(
v: streams.BinaryStream,
headers: HasHeaders,
format: CodecFormat,
charset: Option[Charset]
): MessageResponse = throw Unsupported.Streams
override def fromWebSocketPipe[REQ, RESP](
pipe: streams.Pipe[REQ, RESP],
o: WebSocketBodyOutput[streams.Pipe[REQ, RESP], REQ, RESP, _, NoStreams]
): MessageResponse = throw Unsupported.Streams
}
Notes:
- again,
Anythat needs to be cast to the right type - about half the boilerplate comes from having to not implement the websocket/streaming support
- there is a similar
RawBodyTypepattern match to get the type of the body given back, but this time noRawValuewrapper - we additionally have to put the headers back (which means the conversion from and to a message is not symmetric)
Message => F[MessageResponse]
And lastly, to tie it all together we want to implement the interpreter function that can go between the input and output messages:
final case class MessageTapirBackend[R](endpoints: List[ServerEndpoint[Any, RIO[R, *]]]) {
private[this] implicit val monad: RIOMonadAsyncError[R] = new RIOMonadAsyncError[R]()
private[this] implicit val bodyListener: BodyListener[RIO[R, *], MessageResponse] = new MessageResponseListener
private val interp = new ServerInterpreter[Any, RIO[R, *], MessageResponse, NoStreams](
serverEndpoints = FilterServerEndpoints(endpoints),
requestBody = new MessageRequestBody,
toResponseBody = new MessageResponseBody,
interceptors = Nil,
deleteFile = _ => ZIO.die(Unsupported.Files)
)
def handle(in: Message): RIO[R, RequestResult[MessageResponse]] =
interp.apply(MessageServerRequest(in))
}
Notes:
- the
RIOMonadAsyncErroractually comes from a sttp package rather than a tapir package- there are no other implementations for
ZIO[R, E, A] - it is necessary because tapir does not depend on any other library that defines the basics like
MonadError - I am so far unconvinced that leaving
Throwableas the ZIO error type (withRIO) was the right choice (more on that later)
- there are no other implementations for
- it is unclear why we need the
FilterServerEndpointsand why it is not the default - I am also unsure in what scenarios we would want to use the
MessageResponseListener(that is implemented as a stub) or the interceptors - file deletion is unsupported but required in the interpreter
Have a 🍪, because the brain blood sugar level has surely dropped.
Testing
I decided to test directly with the whole foobar application, including the stub repository that stores all the foobars in memory. Here's what that looks like:
val backend =
MessageTapirBackend[FooBarService.Environment](FooBarServerEndpoints.allRIO())
test("GET /foo should list all foobars")(
for {
// 1. set up test data
_ <- FooBarRepository.store(TestData.Foobar1)
_ <- FooBarRepository.store(TestData.Foobar2)
expected <- FooBarRepository.list()
// 2. run the HTTP method through the backend
resp <- backend.handle(TestData.ListMessage).flatMap(toResponse)
// 3. get data out
got <- parseJson[List[FooBar]](resp.body.get.inner.body)
} yield {
assertTrue(
expected.size == 2,
expected == got,
resp.code == StatusCode.Ok,
resp.header("Content-Type").contains("application/json")
)
}
).provide(FooBarRepository.stubLayer)
// ....
def toResponse[T](res: RequestResult[T]): Task[ServerResponse[T]] =
res match {
case RequestResult.Response(r) => ZIO.succeed(r)
case RequestResult.Failure(failures) =>
ZIO.fail(new RuntimeException(s"failures detected: ${failures.mkString(",")}"))
}
def parseJson[T: Decoder](bytes: Array[Byte]): Task[T] =
ZIO.fromEither(parse(new String(bytes)).flatMap(js => js.as[T]))
This is no different from using any other backend except for the message parsing at the end, which I wanted to do by hand to ensure that things are actually happening as expected within the tapir server endpoints. The tests passed on the first go.
Observations
After I figured out the interfaces I needed to implement, it was a matter of solving the type puzzle (also known as
type driven development). I am sure there are a significant number of people that would balk
at the idea, but in my experience it is a lot simpler than to solve some global mutable state race condition type
heisenbug (or indeed, a gradle build issue, which turns into the same thing). It really only requires listening
diligently to what the compiler is telling you. I haven't had to change the server backend code when I wrote the tests,
though I did have to add type annotations and use .asInstanceOf a few more times than I would have liked.
Using tapir for this exercise, I was glad that only about 120 lines had to be dedicated to dealing with the custom
message handling. Tapir 1.0 only came out in June 2022, so I expect that a 2.0 will at some point
have a lot more ergonomics (and safety, by dropping the use of Any) improvements as time goes on and the design is
refined. The only thing I am slightly worried about is the use of RIO instead of URIO as the F[_]. I think it
means that any exceptions thrown outside the server endpoints' Either[Error, Success] return type will go to a default
exception handler rather than being the end of the server, and as by definition these are really exceptional, it feels
that they should go to "defect"/"die" side of the ZIO error channel. I will try and clarify with the maintainers if my
understanding is somehow incorrect.
Scala 2 is also showing its age. Unfortunately we are still behind on the Scala 3 migration, but there were a few type inference bugs that I encountered and really cryptic error messages that I think I wouldn't have seen in the new version.
So, to summarise: it took about 120 lines to implement a custom backend for tapir that allowed handling arbitrary
message types as HTTP endpoints, and a couple of hours to integrate this all together (plus a good few hours to write
down the experience). The typing complexity is probably quite high though - you are not only dealing with the ZIO types,
but also with the Tapir endpoint definitions, the "capabilities", and the F[_] as a ZIO[_, _, _] conversion. I hope
that this post demonstrates that there is no magic involved and that such an approach is flexible for any type of
messaging system that supports messages with bodies and header key/values.
We gained the following from this approach:
- A clear separation between the protocol (HTTP), the business logic and the transport layer
- A precise description of behaviour for our endpoints
- Some OpenAPI specs
- A client implementation (should we decide to write integration tests going through the HTTP gateway for our system)
- A second server implementation using a real HTTP server that we could use for local testing (since we probably don't want to run the gateway on our dev machines all the time)
On balance, I would call that a win. Code is here - I hope you find it useful and/or educational.